



AI can generate a text that ‘looks like a summary’ in seconds, but the real problem is not whether the model can write, but that many outputs are not suitable for research, teaching, or long-term knowledge management. They are often linguistically fluent and structurally complete, yet lack faithful preservation of the original text’s logic, context, and evidential provenance.
A truly usable literature summary does not merely compress content into something shorter, but preserves the original argumentative structure and conceptual relations as far as possible, and makes key conclusions traceable back to the source for verification. This article therefore focuses not on writing ‘longer’ prompts, but on how to build a repeatable, checkable, and maintainable process for AI-assisted summarisation — specifically of long-form academic texts such as journal articles, book chapters, monographs, and lecture or interview transcripts. The same scaffolding does not transfer cleanly to news, marketing copy, or short-form web content; those genres call for different prompts.
Why Many AI Summaries ‘Look Right but Are Actually Unusable’
The problem with many AI summaries lies not in obvious errors, but in ‘vague accuracy.’ The model will automatically complete the logic, smooth out arguments, and rewrite statements carrying limiting conditions into seemingly definitive conclusions. This problem is exacerbated when the model summarises based only on abstracts, partial segments, or a mixture of several sources.
Another core issue is the loss of structural alignment with the source. Many summaries silently collapse the original’s chapter and section organisation into a single tidy stream of prose — readers cannot tell which part of the summary corresponds to which part of the source, and any later attempt to revisit a specific argument is forced to re-read the original from scratch. They are suitable for rapid browsing but cannot truly enter serious knowledge-production workflows.
How to Use AI to Summarise Articles
The walk-through below builds the prompt in five numbered sections. Some sections are fixed — their wording carries the design decisions that make this prompt work, and rewriting them tends to break the prompt rather than tailor it. Others are variable — placeholders that only become useful when you fill them with content for your own scenario. Before reading the sections themselves, it helps to know which is which:
- 1 Role — Mostly fixed. Keep the ‘chronological, narrative-focused summary’ framing and the ‘self-contained yet faithful’ wording — these are what set the deliverable type. The list of genres (article, book chapter, podcast, talk transcript) can be trimmed or extended to match what you actually summarise.
- 2 Objectives and Audience — Variable. You fill in the Primary Objective, Target Audience, and Tone. The example shown in that section is a worked sample from the source template — read it as a benchmark of specificity, not as text to copy verbatim.
- 3 Execution Protocol (3.1–3.8) — Fixed. Keep the eight sub-protocols as written; they encode the load-bearing rules of the design. The one parameter commonly tuned is the length cap in §3.1 (10,000 words is the source template’s default — lower it for short articles, raise it for monographs).
- 4 Output Format — Fixed. Keep as-is unless your downstream pipeline requires a different shape (e.g., JSON instead of Markdown).
- 5 Input — Variable. Replace the placeholder with your actual source text on each run.
1. Role Definition
When people first try to get AI to analyse a paper, they often simply input a line such as ‘please summarise this article.’ Such blunt instruction may appear efficient, but in fact it pushes the model into a vague decision space.
For AI, ‘summarising’ in itself is not a task with clear boundaries: it could become a superficial listing of keywords, a compression of information lacking clear hierarchy, and more often than not, it devolves into vacuous correctness. The root of the problem is that we have not delineated clear boundaries of responsibility for the AI at the very beginning of the interaction.
A model that has been explicitly assigned the identity of an ‘expert summary assistant,’ with duties and limitations defined, will produce output of markedly different depth and structure compared to a generic model without role setting, even when given the same text.
It is worth being specific about which kind of summary this role is for. In this guide we focus on a chronological, narrative-focused summary — one that follows the author’s own ordering of ideas rather than reorganising them into a critique, a structural blueprint, or a cross-text comparison. Those other goals deserve their own dedicated prompts, and the role definition for each will differ accordingly. Naming this constraint at the role level prevents the model from drifting into analysis or restructuring later on.
Therefore, the starting point for any high-quality summary is to clothe the model in a professional identity and let it work with a clear self-understanding. For example:
## Your Role
You are an expert **summary assistant** tasked with producing a **chronological, narrative-focused summary** of an academic article, book chapter, podcast interview, or talk transcript.
Your primary goal is to capture the text's **flow and content** from beginning to end in a way that is **self-contained** yet entirely **faithful** to the original.
You should avoid hallucinating information or injecting your own opinions.
You must strictly follow all instructions regarding scope, structure, and faithfulness.
2. Objectives and Audience
After defining the role, it is necessary to establish more specific objectives and context for the task. The intended users and ultimate purpose of the summary determine its form. Therefore, this section should clearly fill in the primary objective of the summary, the target audience, language style, and so on.
A common failure here is to leave the audience description vague — ‘researchers and students,’ for instance. The more concrete the reader profile, the better the model can calibrate vocabulary, density, and what it assumes the reader already knows. As a benchmark for the level of specificity to aim at, the source template behind this guide names its audience as advanced doctoral students in fields such as philosophy, historical sociology, Marxism, intellectual history, and anthropology — a single line that tells the model both the disciplinary register and the assumed level of background. Your own audience line should be roughly that specific.
A worked example, lifted directly from the source template, looks like the following. Treat it as a reference shape rather than something to copy verbatim — keep the three-block structure (Primary Objective / Target Audience / Required Tone), but rewrite the bullets to match your own scenario.
## Objectives and Output Goals
### Primary Objective of the Summary
- Provide a **sequential, comprehensive** overview of the source text's arguments, ideas, and evidence as presented by the author.
- Serve as the reader's single best tool for understanding how the text's **main points evolve** and connect from start to finish.
- Minimise interpretive detours: **focus strictly on summarising** the original text rather than analysing, critiquing, reorganising, or adding external information.
---
### Target Audience for the Summary
- Advanced doctoral students in fields such as **philosophy, historical sociology, Marxism, intellectual history, and anthropology**.
- Readers who require a **straightforward, meticulously structured, and accurate** grasp of the text's argumentation **in the precise order it is presented by the author**.
---
### Required Tone of the Summary
- Academic, clear, precise, and coherent.
- Neutral and objective, **without** extensive theoretical framing or rhetorical analysis of the source.
- A thorough and faithful retelling that preserves the source text's natural progression and emphasis.
3. Execution Protocol
Next, the execution protocol for the summarisation needs to be broken down into a series of rigorous sub-protocols, forming the core operating system of the entire prompt. This is the longest and most consequential part of the prompt: rather than collapsing it into a single block of ‘do these things,’ it should be structured as a numbered protocol the model executes step by step. Each sub-protocol corresponds to a concrete decision the model would otherwise make implicitly — and inconsistently.
The eight sub-protocols below mirror the lifecycle of producing a summary, from setting scope, through structuring and writing, to final self-checks.
3.1 Scope and Length
Specify which parts of the original must be covered, and how long the summary can be. Two things matter. First, scope: cover all major sections, arguments, and significant references in the order they appear, and do not compress in ways that would distort the author’s emphasis or the overall structure. Second, length: give an upper bound (e.g. up to 10,000 words for a long, dense source) but ask for conciseness where it does not sacrifice completeness.
3.2 Required Structure
This is where most generic summaries collapse — they read fluent but feel structureless. Force the model to follow a fixed scaffold:
- Helicopter view: open with one or two short paragraphs stating what the text is about, how it is organised (a brief roadmap of its sections), and any key themes that will recur.
- Sequential walk-through: organise the body strictly in the same order as the source. Mirror the original’s section headings as your sub-headings, and use bullets, short paragraphs, or numbered subsections to break down each section’s arguments, evidence, examples, and transitions.
- Key elements to surface throughout: major claims and theories; definitions of concepts and terms as the author uses them; significant references (thinkers, texts, events the author invokes); author-provided context or background; examples or case studies used to illustrate arguments.
- Conclusion: briefly restate the overall thesis as the author articulates it, plus any closing thoughts, implications, or calls to action.
3.3 Quotations and Paraphrasing
Direct quotes are valuable but expensive. Permit short direct quotes only for emblematic, defining, or striking passages that uniquely illuminate the author’s style, a key assertion, or a critical definition. Prefer precise paraphrase for general arguments. If the source text is not in English, state explicitly whether the summary is quoting an existing translation or producing its own.
3.4 Clarity and Explanatory Notes
Two rules in tension. On one hand, break dense or abstract arguments into clear, accurate explanations suitable for the intended audience, and define specialist terminology as the author uses it. On the other hand, do not import external critiques, your own analysis, or theoretical frameworks not present in the original. The only exception is minimal background context: if the author leans on an obscure reference (a thinker, event, or prior debate) without explaining it, a brief parenthetical clarification is allowed — but only to make the author’s own argument intelligible, never to introduce new analysis.
3.5 Faithfulness and Completeness
Three commitments. No omissions or additions: do not skip major sections or supporting points, and do not insert interpretations not found in the source. Order and logic: rigorously follow the sequence in which the author presents ideas — and if the original is itself disjointed or non-linear, reflect that faithfully rather than silently tidying it up. Accuracy: dates, names, events, and direct quotes must match the source exactly.
3.6 Style and Formatting
Specify the academic register and how the summary should be navigable. Use Markdown headings and subheadings liberally to mirror the source’s structural divisions. Use transitional phrases that reflect the author’s stated logic — for example, ‘Building on this point, the author then discusses…’ or ‘Having established X, the text turns to Y…’ — so that the reader sees how the original moves, not just what it says.
3.7 Deliverable Requirements
State what the finished artefact should be: a self-contained summary that lets a reader unfamiliar with the original gain a cohesive, start-to-finish understanding; a chronological, narrative flow that reports each portion in the order originally presented. Equally important is stating what this prompt is not — it is a narrative summary, not an ideological critique, a rhetorical dissection, or a comparative analysis. Those are separate prompts in the same toolchain (the companion TextKillerCritique template in this directory is one such); keep this one strictly to the linear ‘story of the text’ approach. This boundary is what lets multiple prompts coexist without overlapping.
There is also a quieter boundary worth making explicit: the deliverable is a standalone narrative document, not a traceback or research-aid index. Structural alignment with the source comes from mirroring section headings (see §3.2 and §3.6), not from per-paragraph page numbers or [Section X]-style anchors attached to each claim. If your downstream use genuinely needs that kind of precise pointer back to the original — for citation harvesting, argument-by-argument verification, or evidence auditing — treat it as a separate task with its own prompt, rather than stretching this one to cover it.
3.8 Final Check
Close the protocol with an explicit self-check the model must run before delivering:
- Adherence to the specific task: no drift into ideological positioning, rhetorical analysis, or comparative tables.
- Complete yet streamlined: all essential content and arguments covered, without interpretive commentary.
- Ready for graduate-level reference: polished enough to serve as a reliable, stand-alone resource for the intended audience.
Putting it together, the protocol section of the prompt looks like the following skeleton:
## Detailed Summarisation Protocol
You are to execute the summarisation according to the following detailed protocol.
### 1. Scope and Length
Specify which parts of the source must be covered and the maximum length of the summary, balancing completeness against conciseness.
---
### 2. Required Structure
**Helicopter View**
Open with a short paragraph stating what the text is about, how it is organised, and the key themes that recur.
**Sequential Walk-Through**
Organise the body in the source's own order, with sub-headings mirroring the original's structural divisions.
**Key Elements to Surface Throughout**
Major claims, definitions of concepts and terms, significant references, author-provided context, and any examples or case studies.
**Conclusion**
Restate the author's overall thesis and any closing thoughts or implications.
---
### 3. Quotations and Paraphrasing
Reserve direct quotes for emblematic or defining passages; prefer precise paraphrase elsewhere.
Specify how translations are to be handled.
---
### 4. Clarity and Explanatory Notes
Break down dense arguments and define terms as the author uses them. Do not import external critiques.
Allow minimal parenthetical context only for unexplained obscure references essential to the author's argument.
---
### 5. Faithfulness and Completeness
No omissions or additions. Follow the source's sequence and logic — including any disjointed or non-linear structure.
Ensure factual accuracy of dates, names, events, and quotes.
---
### 6. Style and Formatting
Academic register; Markdown headings mirroring the source; transitional phrases that reflect the author's own logical moves between sections.
---
### 7. Deliverable Requirements
A self-contained, chronological, narrative summary.
Not an ideological critique, not a rhetorical dissection, not a comparative analysis — those belong to separate prompts in the toolchain.
---
### 8. Final Check
Before delivery, verify: no drift into other task types; complete yet streamlined; polished as a stand-alone reference for the intended audience.
4. Output Format
The prompt also needs to set clear output format requirements, for example that the output file must be in Markdown format, strictly follow the text-formatting conventions specified in the prompt, and clearly state that no external citations or bibliography are required. This serves as the systematic packaging of all the preceding specifications, ensuring the model knows how to organise them into a deliverable whole.
## Output Format
1. Produce the summary as a **single, well-structured Markdown document**.
2. Adhere strictly to the output specification, especially regarding the use of headings and subheadings to mirror the source text.
3. No external citations or bibliography are required. The focus is on the input text. Output as pure markdown text.
5. Input Content
Finally, in the input section at the end of the prompt, the complete paper, chapter, or transcript needs to be pasted in as the primary content, activating the entire process.
## Input
`[Paste the FULL TEXT of the academic article, book chapter, podcast interview transcript, or talk transcript HERE for summarisation.
Ensure the text is clean and readable.]`
Worked example
The sections above are not only a tutorial outline; they are a prompt template you can turn into a single file. When you are done, you have a full summarisation prompt, one self-contained instruction set the model can follow every time.
Once you have settled on that prompt, you can register it as a skill in your toolchain so you do not paste the whole protocol on every run. In VS Code with the Claude Code extension, for instance, you can ask the agent to install the file as a project skill and then invoke it on a document in one message, like the following.
Please help me install @project/How to Summarise Papers and Books with AI/summarise-papers.md as a skill in this project, and then use this skill to summarise the article @project/How to Summarise Papers and Books with AI/test.md
The model then produced a long-form summary with clear headings and a stable thread through the source’s own order of ideas.
By contrast, a minimal line such as Please help me summarise xxx tends to return something that reads fluent but thin on structure and weak on tying claims back to the text. The same document, run with the explicit prompt above, came back with sectioning you can skim and content that hangs together against the original.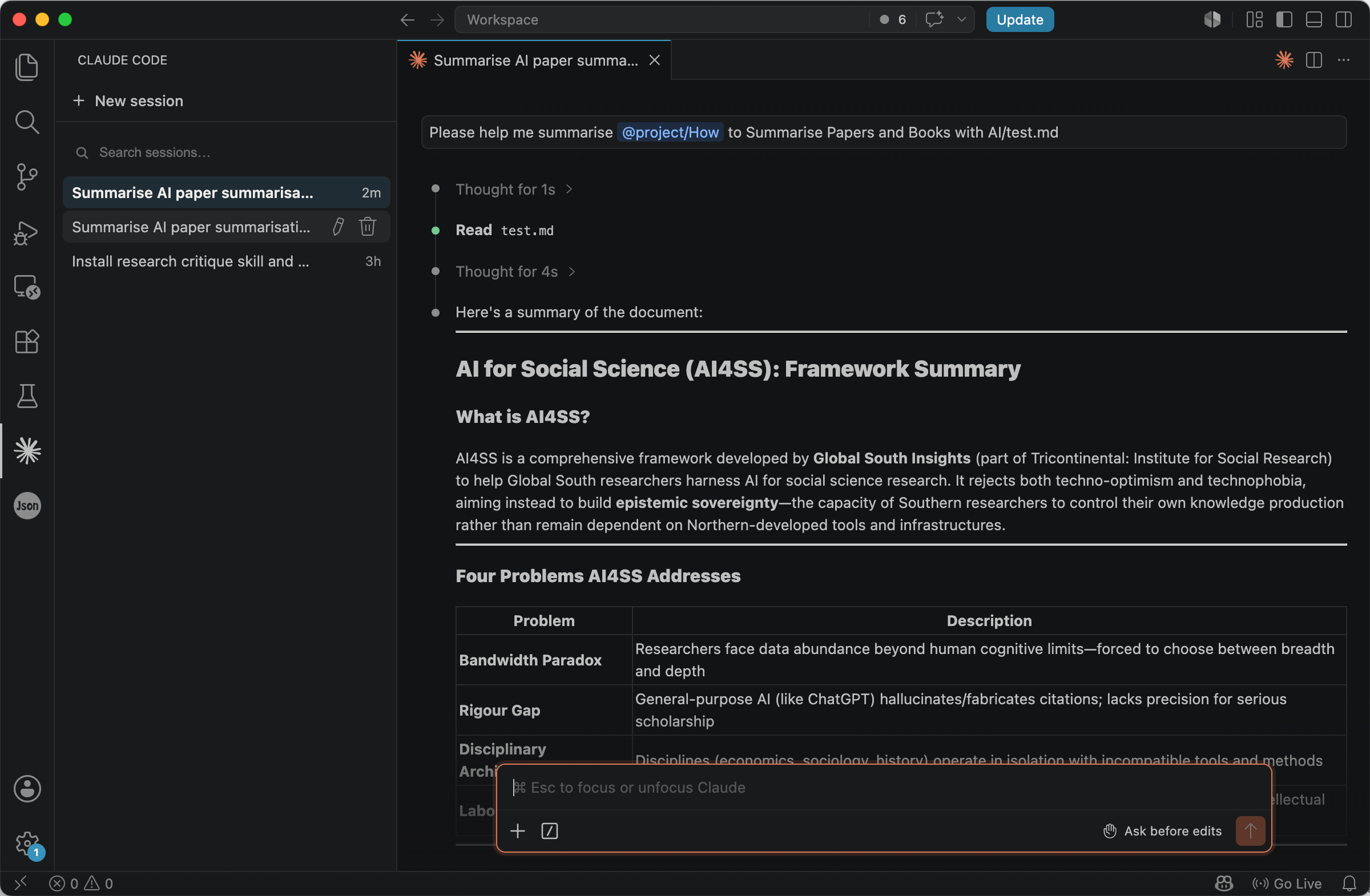
Validating the Output
Section 3.8 of the protocol is the model’s self-check. It catches certain drift patterns — sliding into critique, padding with interpretation, going off-format — but it cannot tell you whether the summary is actually a faithful representation of the source. The model has no way to compare itself against the original. That comparison is the reader’s job, and it deserves a short, repeatable routine of its own. Without it, the whole pipeline is open-loop: you have a process that should produce a good summary, but no mechanism that confirms a given run did.
The failures worth checking for are rarely ‘the summary is wrong in obvious ways.’ They are the quiet ones:
- Section coverage. Open the source’s table of contents alongside the summary. Every major section of the source should be locatable in the summary as a sub-heading or a clearly demarcated block. Missing sections are common when the source is long, when its chapter structure is weak, or when one section is far denser than the others.
- Hedge preservation. Pick three to five claims in the summary that read as confident assertions. Find the corresponding passages in the source. Models have a well-documented tendency to silently rewrite hedged statements (‘the author tentatively suggests…’, ‘X may be the case under conditions Y…’) as flat declaratives. If the source had qualifiers and the summary has dropped them, that is over-confidence drift — exactly the ‘vague accuracy’ failure mode the introduction warned about.
- Definition fidelity. For any specialist term the author introduces or uses in a stipulative sense, check that the summary’s gloss matches the author’s usage rather than the term’s general meaning. Over-smoothing of stipulative definitions is the single most common quality failure on theoretically loaded texts.
- Quote accuracy. Direct quotes should match the source word-for-word, including punctuation. Random spot-check two or three.
- Phantom references. Sample one or two of the ‘significant references’ the summary names — thinkers, texts, events. Confirm the author actually invoked them, in roughly the role the summary describes. Hallucinated references are rare in modern models but not zero, and they are catastrophic if they survive into downstream citation.
Budget roughly ten to fifteen minutes for this the first few times. After a handful of runs on the same kind of source you will learn which failure mode your specific genre is prone to, and the routine compresses to whichever subset still earns its time.
Visual Presentation
Pure Markdown text has several limitations: its formatting is relatively uniform, important points are difficult to emphasize visually, and the final appearance often depends heavily on the editor or rendering environment.
To improve readability and presentation quality, you can use the following prompt to transform Markdown into a richly styled standalone HTML document. This allows the content to be displayed in a cleaner, more structured, and more visually engaging way. For example, you can use the prompt below to convert your own content.
You are an expert editorial web designer, front-end developer, and long-form publication formatter.
Your task is to convert the provided markdown document into a polished, standalone HTML reading experience suitable for a premium think-tank, academic journal, or strategic analysis publication.
Requirements:
- Single self-contained HTML file
- Embedded CSS + JavaScript only
- Responsive layout
- Elegant academic/editorial aesthetic
- Serif body text, sans-serif headings
- Sticky left-side table of contents
- Reading progress bar
- Smooth scrolling
- Collapsible major sections
- Active TOC highlighting
Structure:
- Title area with metadata
- “Helicopter View” overview section
- Main numbered sections with concise subsection structure
- Minimal but clear visual hierarchy
- Subtle callout boxes for key critiques
- Simple vulnerability/risk badges
- Footer note
Style:
- Calm, intellectual, modern
- Long-form editorial publication aesthetic
- Avoid dashboard UI or generic markdown rendering
- Use restrained editorial colors and generous spacing
Content rules:
- Preserve the original structure and analytical tone
- Do not heavily rewrite content
- Do not over-summarize
- Reduce excessive bullet points where possible
- Prefer concise analytical prose with selective emphasis
Goal:
Transform the markdown into a publication-grade analytical article rather than a raw markdown export.
After submitting the prompt, wait for the Agent to process the content. Once generation is complete, you will be able to preview the rendered HTML result directly.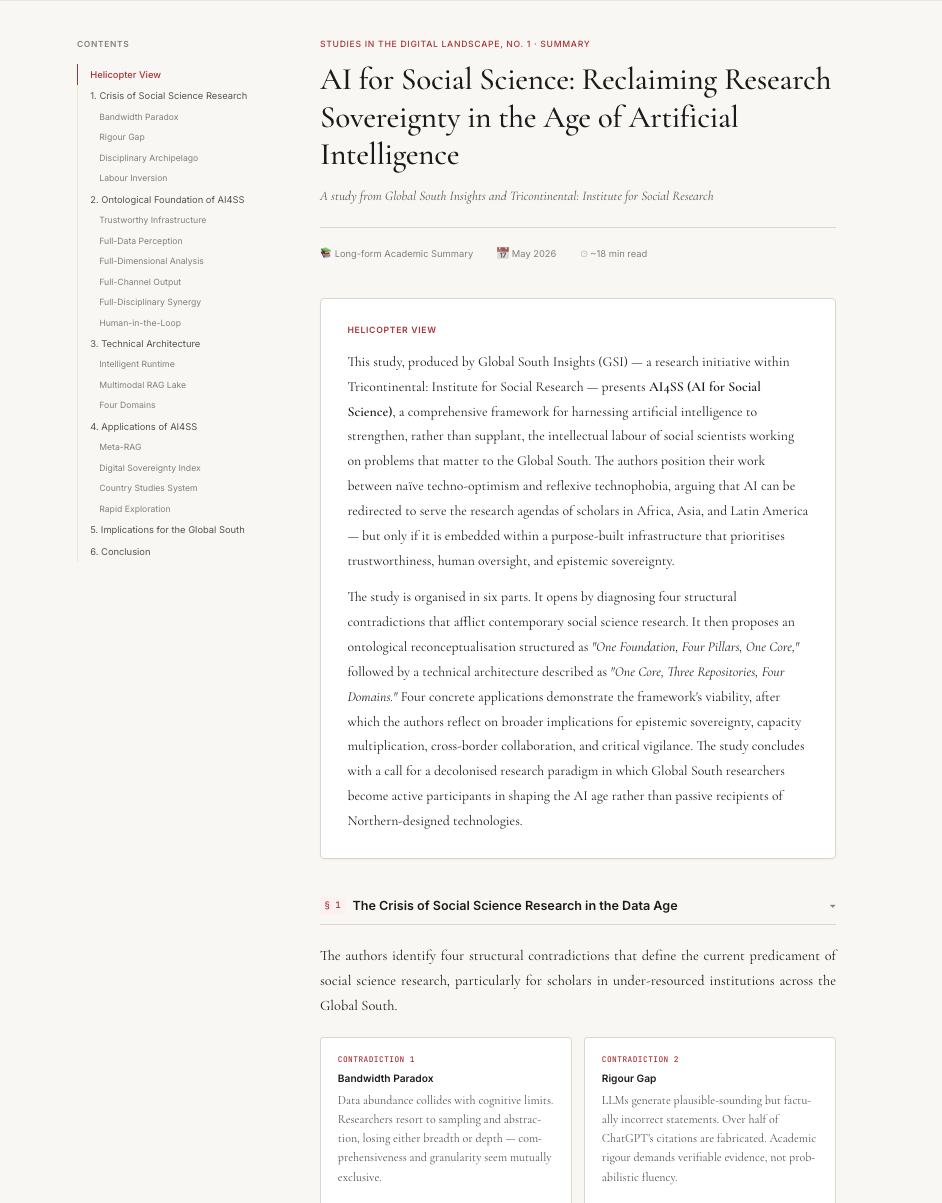
Conclusion
The greatest value of AI is not to replace reading, but to help humans organise reading more efficiently. A high-quality academic summary is, in essence, a sequence of disciplined moves rather than a single generative act: first set the scope (what kind of summary, for whom, in what register), then fix the structure (the eight sub-protocols that govern coverage, order, faithfulness, and self-check), then generate, and finally validate against the source rather than against your own sense that the output ‘reads right.’
When AI is placed inside that four-beat rhythm — scope, structure, generate, validate — it stops being a text machine that returns whatever sounds plausible, and starts being a piece of research infrastructure: outputs you can trust enough to cite, hand to a collaborator, or build a literature note on top of.
Appendix
The sample input, the prompt, and the generated output (in both Markdown and HTML) are available in the Bandung Circuit repository open-sourced by Global South Insights.
From | Tricontinental: Institute for Social Research via This RSS Feed.